AutoGPT x Helicone: Optimizing Evaluation Pipelines
AutoGPT is diligently developing their Auto-GPT-Benchmarks repository. Their goal? To construct the optimal evaluation pipeline for comparing different agents.

AutoGPT is fully leveraging the capabilities of Helicone without modifying a single line of code. Here are the key features that facilitate this synergy:
- Proxy Integration: Helicone’s role as a proxy allows AutoGPT to maintain their codebase intact. Learn more about this feature in our MITM Proxy documentation.
- Caching: For minor code modifications that don’t necessitate re-calling the LLM for an entire CI pipeline, requests can be cached on edge servers. This feature saves AutoGPT over $10 per PR! You can read more about this in our Caching documentation.
- GraphQL: Our data extraction API enables AutoGPT to generate custom reports upon the completion of a CI job.
AutoGPT’s Workflow with Helicone
AutoGPT’s workflow leverages Helicone’s Man-In-The-Middle (MITM) tools. This allows the interception of all traffic that would have been directed to OpenAI from their CI machine and reroutes it to Helicone. Consequently, AutoGPT can now utilize all of Helicone’s features.
Integration
AutoGPT employed a MITM approach to capture all logs intended for OpenAI. Here is a code snippet showcasing how this was accomplished:
bash -c "$(curl -fsSL https://raw.githubusercontent.com/Helicone/helicone/main/mitmproxy.sh)" -s start
Within the benchmarks, AutoGPT implemented a Python library where they could set specific custom properties for detailed measurements, as shown here. You can learn more about this in our Custom Properties documentation.
HeliconeLockManager.write_custom_property("job_id", "1")
HeliconeLockManager.write_custom_property("agent", "smol-developer")
If AutoGPT wants to enable caching, they can do so by simply setting an environment variable like this:
export HELICONE_CACHE_ENABLED="true"
The total integration process required at most 5 lines of code, which enabled AutoGPT to immediately get rich dashboards and save costs on their CI jobs.
Data Ingest
AutoGPT can track how different agents are impacting their costs.
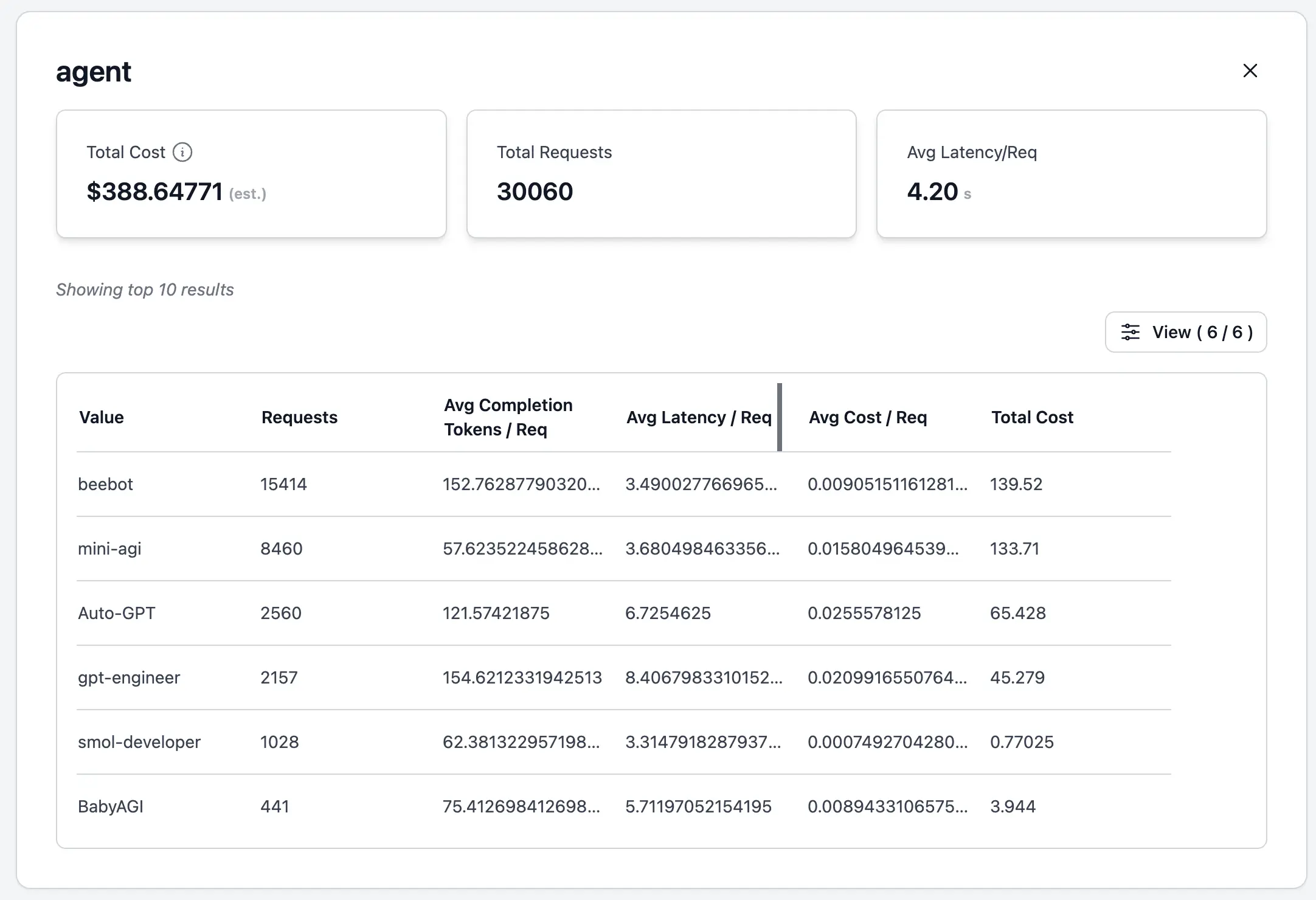 AutoGPT’s agent comparison dashboard
AutoGPT’s agent comparison dashboard
If they wish to examine specific requests, they can do this by using the filter feature.
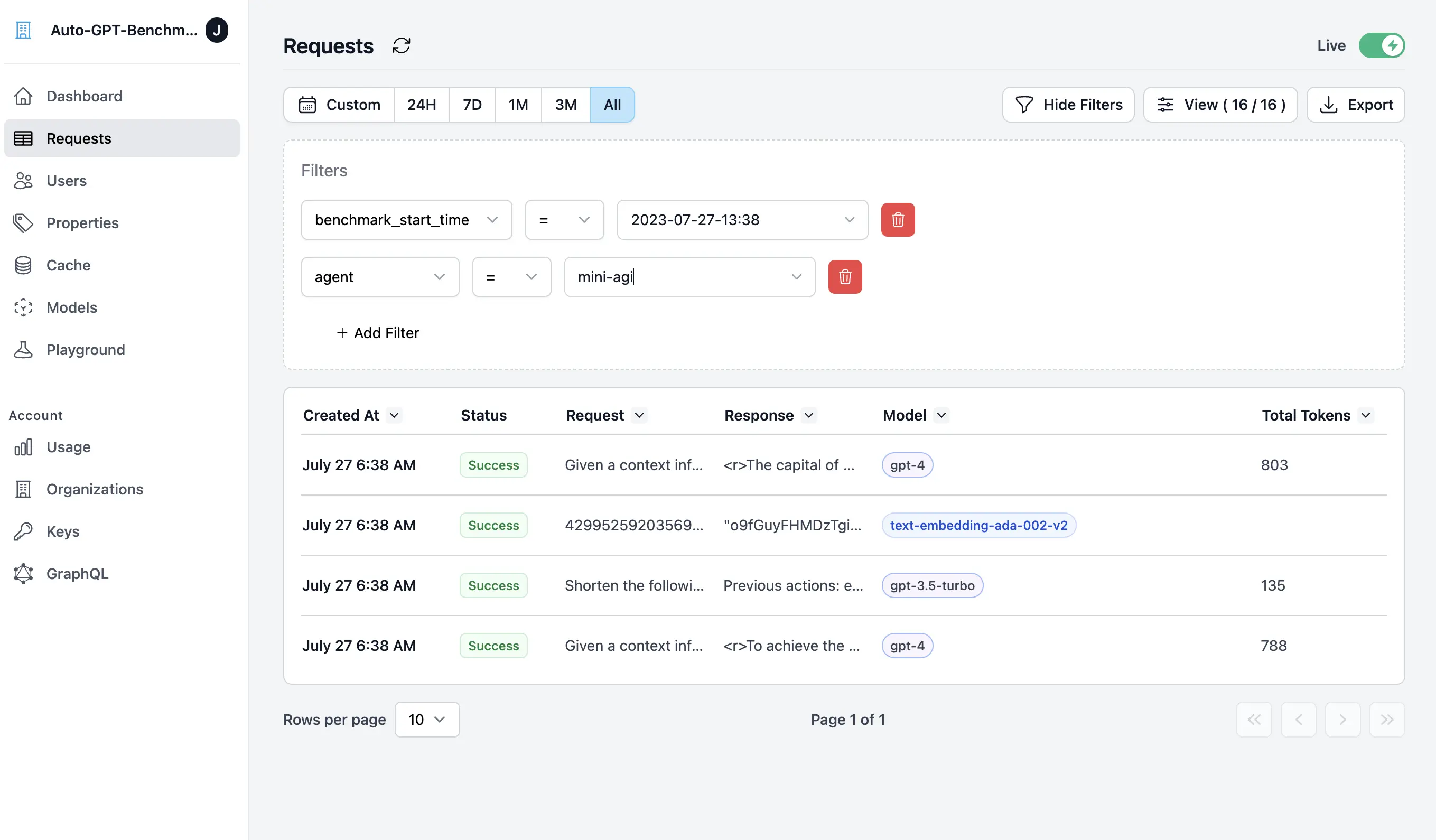 Filtering feature for examining specific requests
Filtering feature for examining specific requests
Determining Cost Savings
For scenarios where testing the agent’s functionality is needed but calling the API is not, such as small code changes, they can monitor their cache usage effortlessly through the dashboards. Here’s an example:
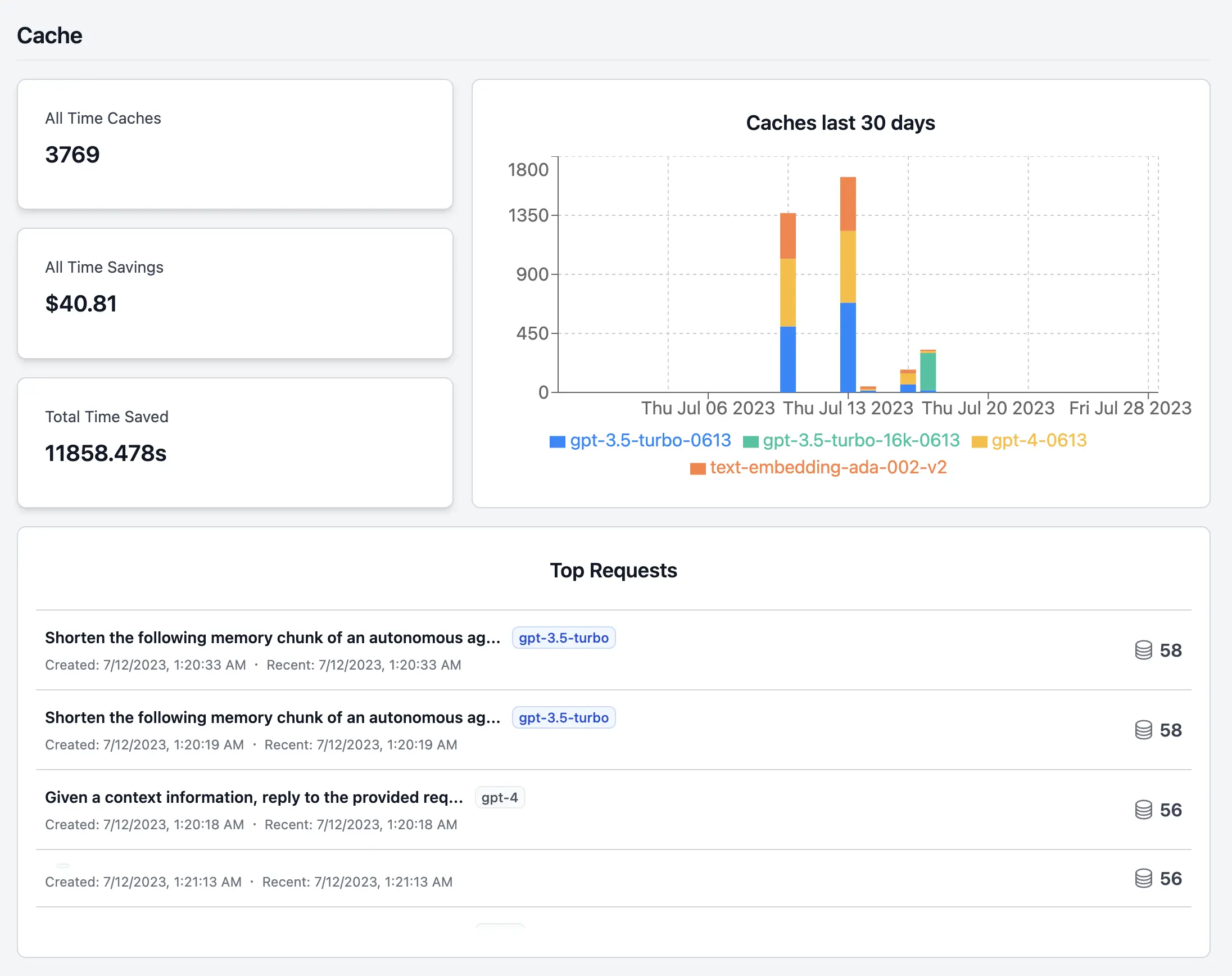 Dashboard showing cache usage statistics
Dashboard showing cache usage statistics
We also maintain a log of each cached request, ensuring that caching is effective and marking agents as “Cacheable Agents”.
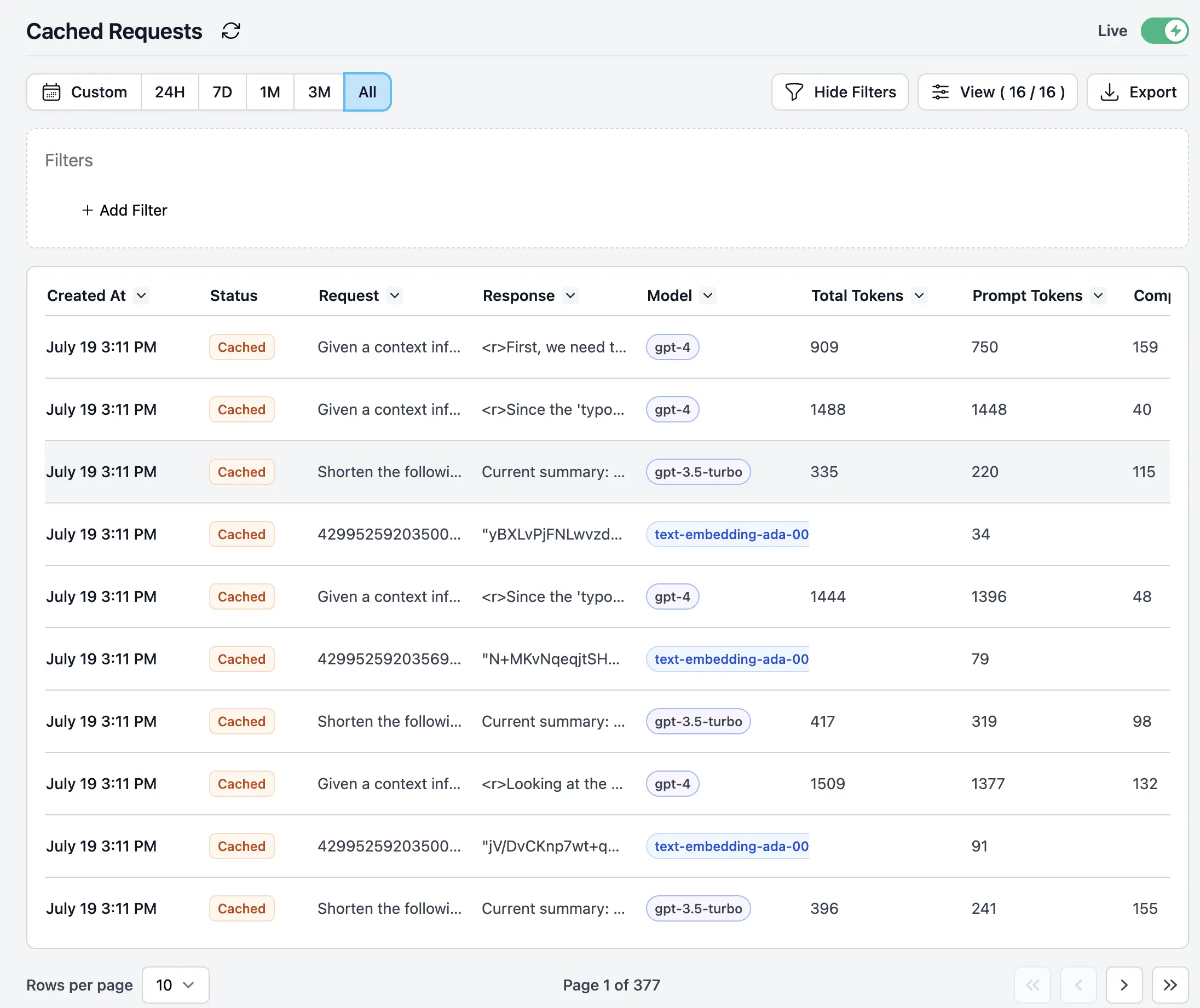 Log of each cached request
Log of each cached request
The Road Ahead
We are currently developing a suite of GraphQL endpoints that will allow AutoGPT to easily ingest some of their data and add it directly to the reports after a run.
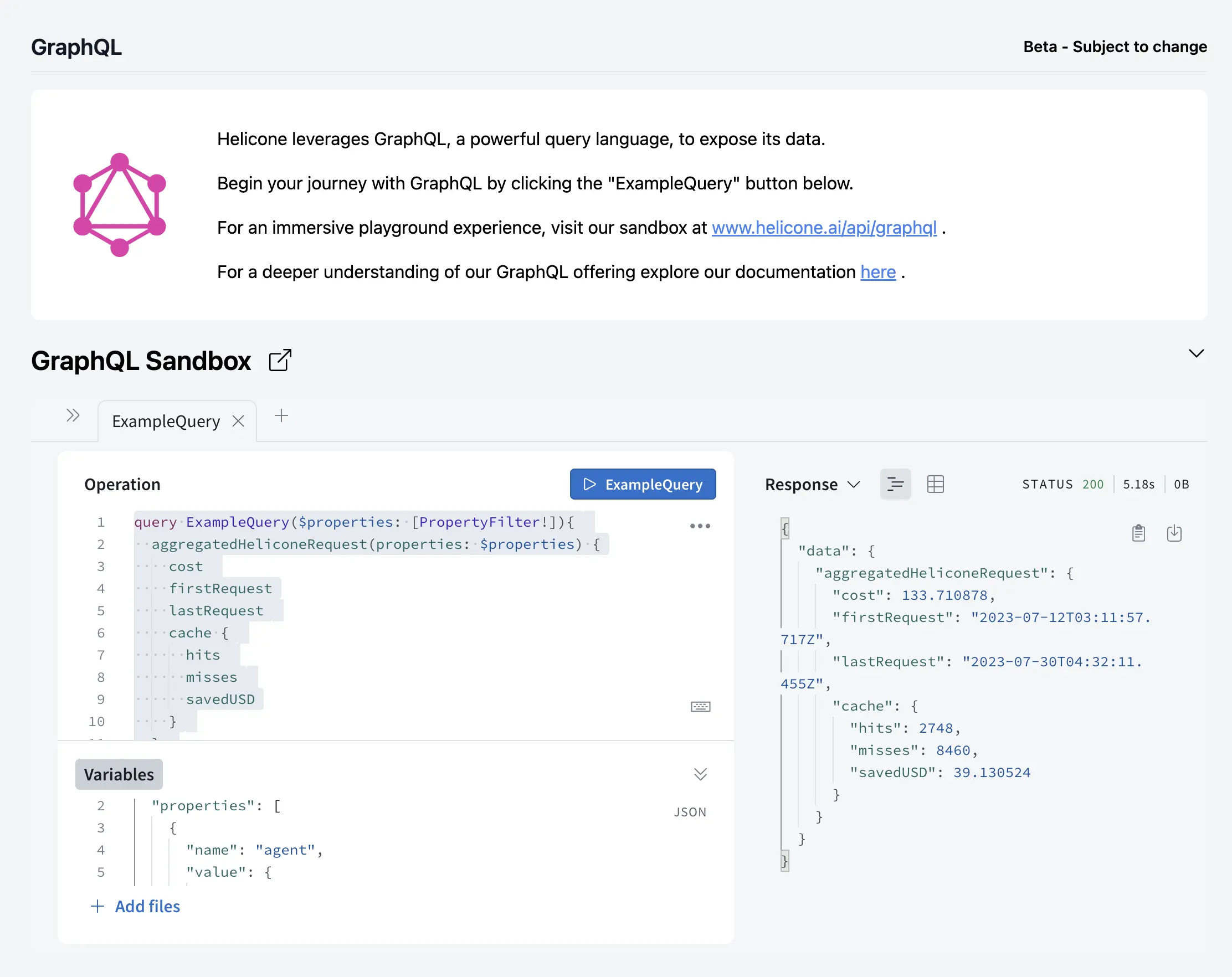 GraphQL endpoints in development
GraphQL endpoints in development
This development is being paired with deep links so that we can have a tight integration between report generation and Helicone. Here is a preview of what a benchmark report will look like:
AutoGPT report
Job-Id: 8AB138BF-3DEA-4E84-BC27-5FE624B956BC
--------------------------------
Challenge go-to-market
Total Cost: 1.234 USD
Total time: 10s
Number of OpenAI calls: 231
Total Cache hits: 231
Cache $ saved: $231
Link: https://helicone.ai/requests?propertyFilters=%5B%7B%22key%22%3A%22challenge%22%2C%22value%22%3A%22got-to-market%22%7D%5D
Model breakdown
| | gpt4 | claude | gpt3.5 |
|-------------------|-------|--------|--------|
| cost | $32 | $32 | $32 |
| prompt tokens | 42141 | 12 | 213 |
| completion tokens | 1234 | 124 | 23 |
| # of requests | 231 | 3 | 312 |
Challenge send-email
Total Cost: 1.234 USD
Total time: 10s
Number of OpenAI calls: 231
Total Cache hits: 231
Cache $ saved: $231
Link: https://helicone.ai/requests?propertyFilters=%5B%7B%22key%22%3A%22challenge%22%2C%22value%22%3A%22send-email%22%7D%5D
Model breakdown
| | gpt4 | claude | gpt3.5 |
|-------------------|-------|--------|--------|
| cost | $32 | $32 | $32 |
| prompt tokens | 42141 | 12 | 213 |
| completion tokens | 1234 | 124 | 23 |
| # of requests | 231 | 3 | 312 |
-------------------
Challenge Comparisons
| | send-email | go-to-market |
|-------------------|------------|--------------|
| cost | $12 | $32 |
| prompt tokens | 42141 | 12 |
| completion tokens | 1234 | 124 |
| # of requests | 231 | 3 |
Thank You for Reading!
We appreciate your time in reading our first blog post. We are excited to be partnering with AutoGPT to enable rich logging for them and deliver value using Helicone. If you are interested in learning more about Helicone or would like to meet the team, please email me at justin@helicone.ai or join our discord!